Understanding Generative AI
March 2025 , Sam Moreland
Now there are a lot of buzzwords and obfuscation around AI. Some of this is deliberate to generate hype, some of it is necessary to deal with a complex evolving field. With this article I hope help you understand what generative AI is and its use cases. I’m not going to dive into the maths and code, but will give a high level understanding of how it is “thinking”. If you want to understand more about the fundamentals of neural networks 3blue1brown has a great video series explaining them.
What is AI/AGI?
In current terminology AI are models based on neural network architectures. Neural networks have different levels of capabilities and use cases. Some AI models are great at classifying images of x-rays. Some AI models can detect fraud or correct your grammar etc.
The biggest shift recently came from the explosion of Large Language Models (LLMs) like ChatGPT and Claude. Here we can interact with AI on a conversational basis for the first time. This is enabled through transformer architecture which is a type of neural network first introduced by google in 2017. These types models have come to be known as Generative AI (GenAI).
There are a few other types of models also included in GenAI umbrella (diffusion models are used to create images), but this article will focus primarily on transformer architectures and LLMs.
Artificial General Intelligence (AGI) is an AI model with the capabilities of a human. While LLMs are very good and emulate sentence structure to impart information, they are not good at “conceptual” learning. Conceptual learning means that they can reason about the world from its starting component parts. While they can sometimes appear to reason or show an understanding of concepts, much of what they do is pattern matching. They don't inherently break down concepts into fundamental components and then reason from those parts in the way humans do.
Why Generative?
What sets out generative AI (GenAI) apart is the size and type of the model, and what its being asked to do.
Transformer architectures allow for much more efficient learning on text based (or text and image) tasks. This means that models can be much bigger and much more complex than ever before. Because of its efficiency, OpenAI was able to use an order of magnitude more data to create the chat models that we use today.
The term 'generative' means that these models can create outputs that appear 'new.' However, while they generate novel combinations of words, images, or other data, they do so based on patterns learned from the training data. In other words, the outputs are new in their specific arrangement, but they are not entirely divorced from what the model has previously seen. Whether or not humans can do that is an interesting philosophical discussion (see Platos Cave).
How LLMs learn?
A very high level overview of how LLM GenAI works is by taking all of the information scraped from the internet (and other media) and compress it into a size that is able to be queried using natural language. It then decompresses it to answer your question. This compression/decompression is “learned” through a 2 stage process (there are more steps but this is the highest level view).
First can we just take the initial input and see if we can reproduce it from the compressed data, known as auto-regression. They do this by taking partial parts of a sentence and trying to predict the next word. Think how would you finish ”The Cat sat on the X”. This is the generative part as it is learning to generate the next output based on the information provided.
Second stage once it can reproduce the information to a reasonable degree, its trained on answering questions accurately in a way humans can understand, known as reinforcement learning human feedback (RLHF).
Some processes also include specialised training on curated data sets.
By doing this process they are training the model to be able to learn how to store information in a compressed way (patterns) that can successfully generate an answer to a human questions.
Why is compression important to understand?
Compression is important for two reasons, size and concept building.
Size
You start with something with a huge amount of information (size) and want to reduce it to make it more usable. The amount of information on the internet is huge and in order to make it usable (on current hardware) we need to make it smaller.
If you compress something a lot it can become lossy, this means that it loses some information in the process. You can think of this as removing pixels or reducing the number colours in an image. If you compress something a little bit, you may get some blurry colours but the overall understanding of the image is there. But if you compress it too much you may loose important information that is important to be conveyed by the image. The image below shows a good understanding that a meeting is taking place with coffee, but in the compressed image its difficult to know whats going on behind the car. This may or may not be important depending on what you are using the image for.
This happens in LLMs. The reason LLMs have been getting better is that the size is getting bigger to allow more information/patterns to be embedded into the model at higher fidelity.

Fig 1 - Uncompressed image (left), compressed image (right)
Concept Building
On the other hand, concept building is core to trying to get to generalised learning. It’s where you try to relate similar concepts or things together in the same (or close) space. Then the assumption is that things close together in this space are related.
Let's take an example, you have a shelf with 4 boxes in it. You are tasked to group peoples photos into each box so it's easy to retrieve their photo. Each box can only hold 1 photo but you can label the box whatever is easiest to help you remember.
I have 4 photos, Steve, Jeff, Clive and Joe. They are all men with the same haircut and different-colored hair (blue, yellow and red). I need to put their photos into 4 boxes to give to customers when they request them. This is great, as I have the exact number of boxes needed to store the photos so whenever anyone asks for a photo of anyone, I can give them the exact photo. No compression takes place.

Fig 2 - Example of uncompressed storage
But what happens when I get a new photo? I now have the Jane photo who has long blue hair, giving me 5 photos in 4 boxes. How do I order the photos in the boxes?
It's very lucky because Steve and Jeff look exactly the same, they often get mistaken for each other. I can just use the one photo for Steve and Jeff and make a Steve/Jeff box. This is lossless compression as no information is lost.

Fig 3 - Example of lossless compression
Now I’m being asked to add the dog Crumble. How would I organise this? I think Crumble needs his own box as if anyone asks for a photo of a human and they get a dog then they will laugh at me.
Now the 5 images of people need to go in 3 boxes and I have 2 options.
I could organise by gender. I have a female Jane box, a Steve and Jeff Box and merge Clive and Joe.
I could orgnaise by hair colour. I have Steve, Jeff and Jane in one box, Clive and Joe get their own boxes.
If it's more important to get the gender right I need to merge Clive and Joe, but by averaging their photos I get someone with Orange hair. If I decide to keep the hair colour right the Jane/Steve/Jeff box now has someone with middle length hair. This is lossy compression, we cant keep all the photos exactly as they were.
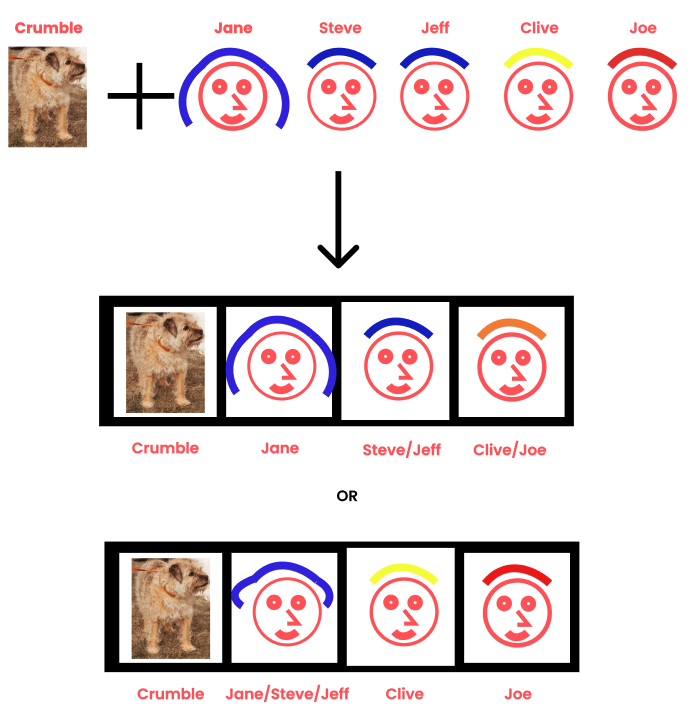
Fig 4 - Example of lossy compression.
This is what happens in neural networks. Depending on the use case, similar things are grouped and merged together into one cohesive thing, but you lose fidelity in the answers. If you need 100% right answers then LLMs cannot do this for all data. However if you're wanting to make things related it can be very useful. For example if I wanted to write a story about a pirate, I have lots of information around what pirates are like compressed together to make something believable, but it might not be 100 % accurate about one pirates biography.
This loss of information is partly where hallucinations come from. The network loses information and relates things together that may or may not be right, and it doesn’t “know” that it's wrong because the information has been lost. In the example above, it no longer doesn’t know that Clive and Joe do not have orange hair because they are compressed, it “thinks” they have orange hair.
Because the network is trained to be the most “right”, things which are more common are prioritised because they have a higher importance (weight). Let's look at the last example again, but this time we’ll add the number of times each photo is requested each day.
Steve is super popular with 1 million requests a day, with Jeff running up with 1 thousand requests. Jane and crumble are new so they only get 100 requests a day, with Clive and Steve not being very popular with only 1 request per day.
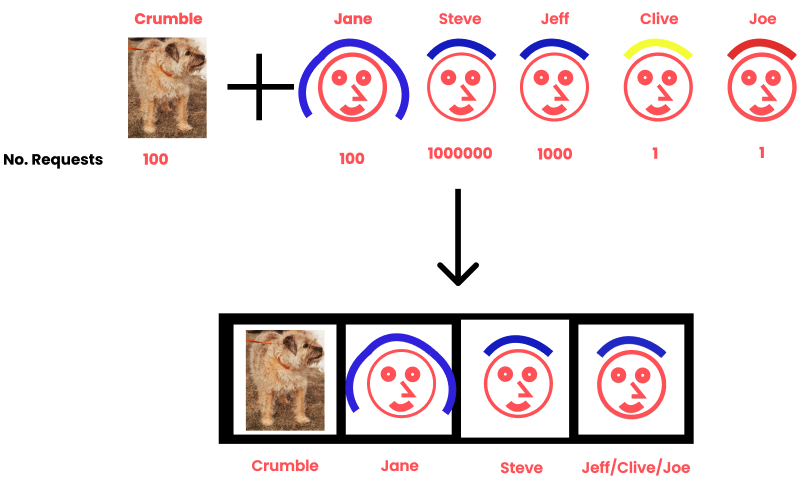
Example of lossy compression with different request amounts.
Because Steve is super popular, he gets his own box. I could have all 4 boxes with just Steve and overall I would still be incredibly accurate because Steve is so much more popular than anyone else.
Jane gets her own box as she's the only female. That leaves the last box with three hair colours to choose from. Because Jeff gets 1000 times the number the request of either Clive or Steve, the hair colour will be blue. This means we’ve lost the colour information for Clive and Joe.
Now neural networks don't think like this exactly, they use linear algebra to compress the information based on the rewards for being “right” i.e. serving enough of the correct photos. But you can imagine as you start to explode the range of what you are being asked to retrieve (photos of spacecraft, music, poetry), the way the data are compressed becomes extremely important.
What does this mean for me?
Essentially LLMs act like a large data storage system that we can communicate with in very flexible ways. You don’t have to learn SQL or scroll through endless google search results. You can blend styles together easily and recreate images from what you are asking the model to retrieve. Because they learn patterns (repeated structures) anything that is extremely common tends to be fairly accurate, but anything that is niche or rare will not be good.
But this is where humans differ. Imagine you are a doctor with a patient and they come in with something very serious and novel that you’ve not seen before or requires a new technique to treat. That patient is likely to become seared in your mind. This does not happen with AI unless the data is very heavily understood and weighted (which requires a lot of human validation).
LLM performance will continue to get better but there will always be cases where it will hallucinate. There are methods to reduce this such as RAG but it does not solve the core issue, its kind of a work around. If you have tasks which are very repetitive with defined outcomes and low edge cases, the current technology is great. If however edge cases are extremely important like healthcare, then you need to be very careful in its utilisation.